Introducing Universal Gestures

Waterloo Reality Labs has developed 5 on-device machine learning models that can recognize complex hand shapes from a first-person perspective.
Releasing today to Unity developers in preview, Universal Gestures raises the bar for ease-of-use and accessibility when implementing gesture recognition in VR.
Background
When developing VR applications in Unity, software developers have limited forms of input to work with. As opposed to web or mobile applications, where users have access to touchscreens or keyboards, VR apps must rely on the hands as the primary input method. Therefore, mapping hand gestures to actions in your app is a crucial step in developing an intuitive experience. For example, using a thumbs up to confirm a purchase in a shopping app, or making a complex shape with both hands to summon a spell in a video game.
There are previously existing methods to tackle the challenge of hand pose recognition. When developing for Meta Quest headsets (the most popular XR headset by market share), Unity developers can use the Meta XR All-in-One SDK. This SDK allows developers to access measurements about the position of each finger, then create a custom gesture by configuring various components, such as FingerFeatureStateProvider and ShapeRecognizerActiveState.
There are several drawbacks to this existing solution:
- It is technically challenging to configure, and requires the developer to have a solid technical understanding of what's happening under the hood. In order to simply set up recognition for a two-hand gesture like heart hands, you must configure thresholds for up to 4 different measurements for each of the 10 fingers. You must also configure up to 5 Meta scripts for each hand, with further complications if you want to consider how each hand is positioned relative to one another. Throughout the setup process, it is easy to make configuration mistakes or drag in incorrect references, leading to development delays. Developers on our team have personally been challenged by this system when building VR apps at hackathons.
- It requires the developer to learn some anatomy terms in order to understand the different Finger Features (Curl, Flexion, Abduction, Opposition). We find this to be unintuitive: mobile developers don't have to understand the various challenges involved with touchscreen digitizer input, so why must VR developers deal with this higher barrier to entry?
- Hand pose detection is strict and deterministic using this method: either you are making the pose with your hands, or you are not. However, what if a developer wants to recognize a peace sign gesture, with the thumb either in or out, and with tolerance for a wide range of index and middle finger angles? You can configure thresholds with tolerance ranges, but once again it is technically challenging and non-flexible.
As an alternative, we imagined a solution that could accomplish the following:
- Allow users to set up their own custom gestures simply by performing it, and within seconds it becoming usable in Unity
- No additional complexity in setup if you want to recognize two-handed gestures with complex shapes
- Could recognize gestures with millisecond latency
- Could recognize moving gestures, such as clapping
- Enables greater accessibility, since developers can train flexible gesture options for people with limited ranges of motion
- Unlocks new intuitive use cases, such as allowing VR gamers to map their own custom gestures to in-game actions, as simply as changing a key bind
Today, we are excited to release a preview version of Universal Gestures, which is a realization of this solution. By applying a variety of neural network architectures along with Unity Barracuda and ONNX Runtime, hand pose recognition is now simpler than ever. Developers can train their own custom gestures in our training scene with zero knowledge of ML, without ever leaving Unity or writing a line of code. Below, we break down the methods we used to build it.
System Design
When developing for Meta Quest devices, we aren't given free access to hand-tracking cameras due to privacy concerns. Therefore, we are limited to a set of metrics describing the hand skeleton that Meta/OpenXR provide to us through their SDKs. We choose a set of inputs that, when combined together, are enough for a neural network to accurately classify a hand pose in practice. These inputs include floats describing individual finger shapes (Curl, Flexion, etc.) and floats describing each hand's relative position to the other (relative X, Y, Z distance, sine and cosine of relative rotation).
Training the models
The inputs used for our neural network are collected and made accessible to other methods using the UGDataExtractorScript. Now, we can read important metrics about your hand shape in the form of an array of float values.
Next, we must train our model architecture to recognize your gesture of choice. Our models use supervised learning, meaning we need a labelled training set to learn from. For example, if we were training our model to recognize a bunny ears gesture, we need several snapshots of the bunny ears gesture that we label with “1” or “True”, and several snapshots of many other gestures that are not bunny ears that we label with “0” or “False”. Using this data, a neural network can learn to classify any gesture that we feed in as “being bunny ears” or “not being bunny ears”.
We make it easy for developers to create their own dataset with no ML knowledge. By simply plugging in their headset and running our training scene in Play Mode, you can press buttons in VR to begin recording positive or negative training examples. You can then simply perform the relevant hand gesture, and our Data Writer script will run in the background, taking snapshots every frame and labelling them for you.
When you've collected enough training data, it's time to train your model. Developers simply need to launch a Flask server that we've developed onto their local machine by running a single console command. This server makes our PyTorch model architecture and training loop available via an HTTP API call. Then, developers hop back into VR and press a button to train their model. A local API call is made, the PyTorch training loop runs on your own hardware, and the trained model weights are saved as a .onnx file on your machine.
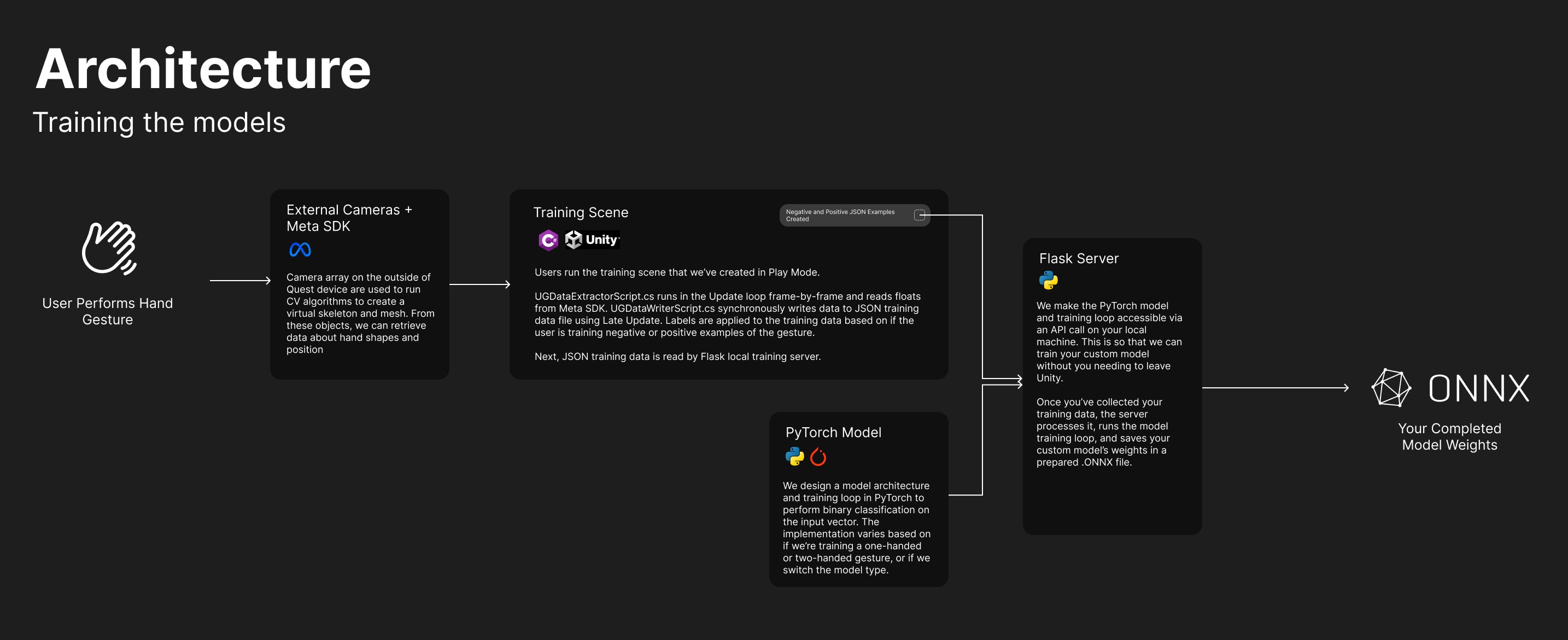
Fig. 1: A diagram depicting how data flows from the external cameras on your Quest device through our training pipeline. Click to expand.
Server? Does that mean the data that I save is being sent over the Internet at some point in the training process?
No. Our entire training pipeline is run solely on your local machine. We use a Flask server and API so that our model loop can be run without ever having to exit Unity Play Mode. Additionally, once models are trained, they can be run entirely on-device using the Quest 2/Quest 3's chip. They can also be used on Windows running a VR application through Quest Link.
How computationally expensive is the process of training these models on my own computer?
Universal Gestures models are designed to learn a gesture in just 5 epochs of training. From a user perspective, training is complete in a blink after pressing the button.
These models use supervised learning and rely on quality datasets. What if the user doesn't record a broad range of training examples?
Before negative training examples are passed to the Flask server for training, we enrich them with synthetic data that covers a broad range of random hand poses. We use a Python script that generates finger positions with enough "distance" to your positive examples, and then add them to the negative data pool. This way, your model won't recognize false-positives regularly.
What's the compatibility of this package? Does my dev machine need to be Windows? What about my build targets?
All our dev tooling is OS-agnostic: as long as you have a Python installation and install Universal Gestures using the Package Manager, you're good to go. Once you build your final application, your app can run on any VR platform: either Quest-native or on Windows using Quest Link.
Running the models
Once you have your trained model in .onnx format, it's straightforward to set up gesture detection. Simply drag in a prefab that we've created, select your model, select a function to run when your gesture is detected, and configure 1-2 settings. Just like that, you can run anything in Unity when your gesture is detected.
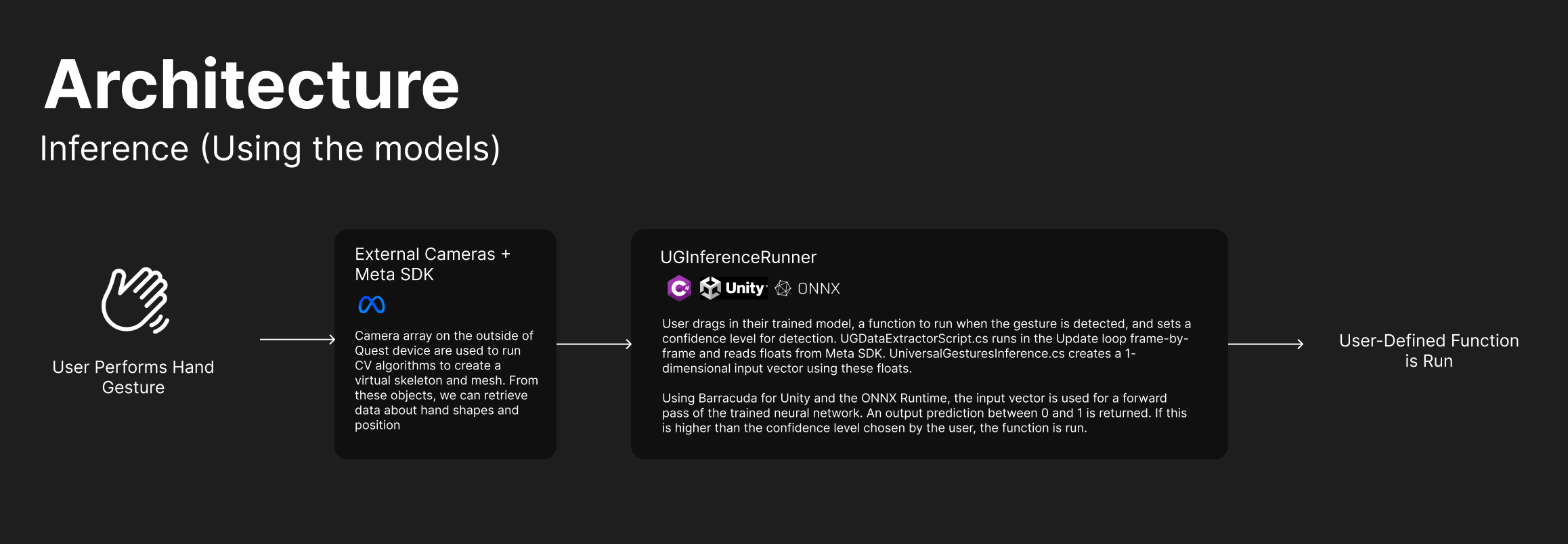
Fig. 2: A diagram depicting how inference is run on models once they are trained. Click to expand.
Benchmarking our models on Mac (M2 Pro), we get the following metrics on performance:
- Average Latency: 0.02081 milliseconds. The mean time to complete one inference pass, showing typical performance
- Latency Standard Deviation: 0.00355 milliseconds
- P95 Latency: 0.02467 milliseconds. 95% of all inference passes perform faster than this. This metric shows consistency in model performance across many passes
When running on-device on Quest 3, we apply the ONNX Runtime via Barracuda, accelerating performance and keeping resource usage low. This translates to no dropped frames in your app, even when on battery and with multiple of our models running inference in parallel.
Model Types
In order to power a variety of use cases, Reality Labs applied a variety of network architectures to build 5 different machine learning models.
One-Handed Static
Our simplest and fastest model recognizes a single-hand gesture, using 17 inputs about finger positions and shape. Our static models are built using feedforward neural networks performing binary classification. The loss function used for optimization is Binary Cross Entropy (BCE). The sigmoid activation function is used to introduce non-linearity. The single-hand neural network uses one hidden layer with 100 neurons, and produces a prediction using 1 output neuron.
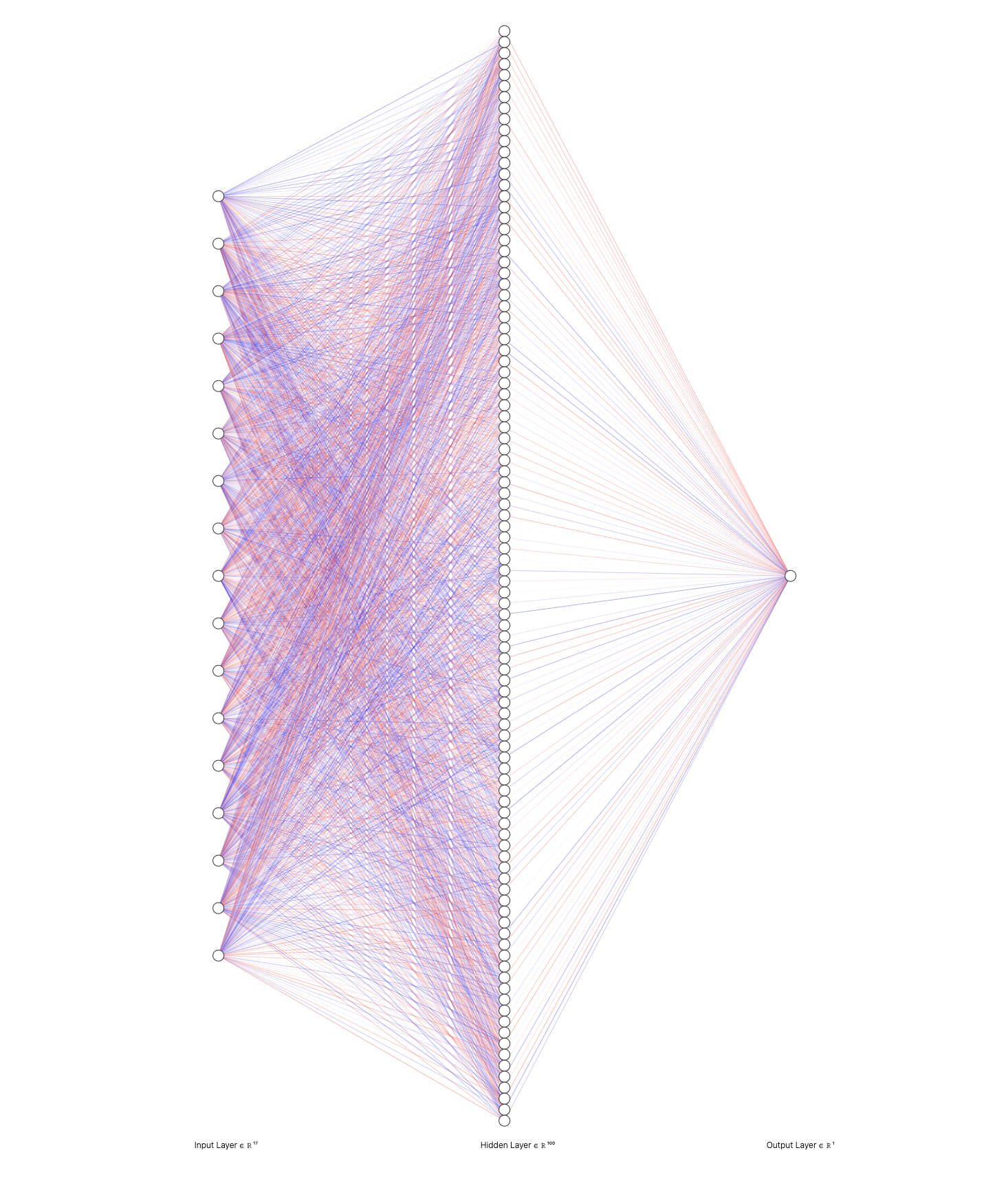
Fig. 3: Visualization of single-hand classification model upon initialization, showing neuron structure and fully-connected layers.
Two-Handed Static
Our model for detecting two-handed gestures uses similar methods to the one-handed model, but with new inputs. In addition to adding 17 new inputs for the second hand, we also need more data describing how each hand is positioned and rotated relative to each other. Without this information, our network would incorrectly identify a heart-hands gesture even if both hands are far apart, or rotated incorrectly.
In terms of relative positional data, we provide the model with the differences in the X, Y, and Z coordinates, alongside the computed Euclidean distance, between the two hands, making it straightforward for the model to learn how the hands should be positioned in 3-dimensional space. Providing the model with relative rotational data is slightly more complicated for multiple reasons:
- First, angles can be expressed as either Euler angles or quaternions. While Euler angles are more intuitive than quaternions (they are the classic rotation values along the 3 axes), they can suffer from a problem known as gimbal lock, whereas quaternions do not. Regardless, we proceeded with Euler angles, since they added less complexity and were sufficiently accurate for our use case.
- Second, since angles are expressed from 0 to 365 degrees, there were issues when a model was trained on data at the threshold. For instance, if the rotation of the hand was near 365 degrees, around half of the data would report very large angles (~365 degrees) while the other half would report very small angles (~0 degrees, since rotating past 365 degrees returns to 0 degrees). This would skew the data and make it difficult for the model to learn patterns regarding rotation.
We circumvent this issue by computing the sin of the angles and using these as inputs rather than the raw angles. This, however, raises a separate issue: the sin function has multiple angles that map to the same output (ex. sin 60° = sin 120°). Hence, if the model for a gesture was trained with input angles of 60°, it would falsely classify angles of 120° as the target gesture. We solved this by using both the sin and the cos of angles as inputs, allowing the neural network to use both to uniquely identify input angles while still avoiding the original issue of the 0/365° threshold.
Finally, to apply these findings, we computed the difference in the X, Y, and Z rotations of the two hands, and took the sin and cos of these angular differences, yielding 6 new parameters to analyze relative rotation. Together with the positional parameters, the two-handed model is capable of effectively recognizing a variety of two-handed gestures.
One-Handed and Two-Handed Dynamic (Release Early 2025)
The above model architectures work for detecting non-moving gestures, since we can simply take snapshots of hand poses. But what if we wish to detect a moving gesture, such as clapping? A simple feedforward network won't be able to tackle this problem as effectively.
For this use case, we opt to use LSTM (Long Short-Term Memory) neural networks as our architecture. LSTM models are recurrent neural networks useful for sequence learning : training a model to recognize a set of tokens in a certain order. For example, LSTM models can be useful in natural language processing, since these networks are able to learn grammatical dependencies between words (learning that after outputting Justin, a likely pronoun is "him").
Our dynamic gesture detection problem is essentially a time series classification task. Instead of trying to classify a single snapshot of a gesture, we take several snapshots of the hands from evenly-spaced out frames over several seconds. We can then format this data as a sequence of input tensors. The LSTM architecture is useful here, since it is able to learn and apply context between individual snapshots. For example, if we are training the LSTM model to identify clapping, it is ideally able to read a sequence of snapshots such as [hands apart, hands clasped together, hands apart] and understand that each snapshot in context of each other constitutes clapping.
We implement the LSTM model using PyTorch. We modify our data recording system in Unity to record training examples in a sequence format rather than static. The user follows a similar training process, recording positive and negative examples for supervised learning. Once training is complete, model weights are also made available in .onnx format and are ready to use in VR.
Few-Shot Static (Release Early 2025)
Is it possible to refine our training process to be even simpler? What if we only required the user to perform the gesture once, without the need for negative-label examples, and then our model would learn it immediately?
One architecture that we've seen promising results from is the Siamese Neural Network. In summary, these artificial networks are trained using a large pre-collected dataset of hand snapshots, and attribute a similarity score to new gestures that are passed in. Unlike feedforward neural networks in our use case, Siamese networks are able to…
- Learn and generalize well using very few instances of a new class. Using its existing repository of learned classes, the Siamese version of our model is able to learn to detect the new class using its similarity score versus existing classes. This means that the user may only need to perform the gesture for a single snapshot, and then the model can detect it accurately.
- The user does not need to provide negative-labelled example gestures, further increasing simplicity in the user experience.
- Training time of the network can be further cut down, since Siamese networks don't require full re-training from the ground up to add a new class.
- Our Siamese model performs multi-class classification rather than binary classification, meaning users won't have to run many feedforward networks in parallel. This could translate into performance & efficiency gains.
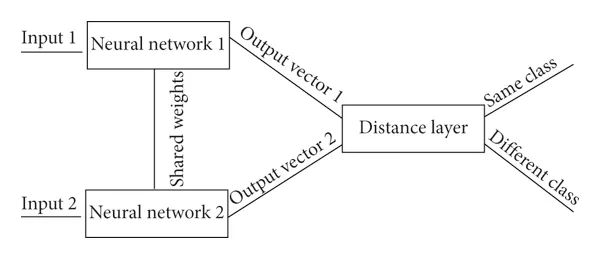
Fig. 4: Diagram depicting a twin-network setup of a Siamese neural network. Two identical networks with shared weights perform forward passes on two different inputs. Often one of these forward passes is precomputed. Once we have two output vectors, we can compare them to see if they are similar enough to be a part of the same class, or if the second output is in a different class.
In PyTorch, we leverage triplet loss for a few-shot learning approach. This approach was particularly effective in reducing the dependency on labeled data, as it focuses on learning relationships between samples rather than classifying each sample independently. The model achieved a significant performance improvement, with accuracy increasing by 29.66% in a few-shot learning benchmark (from 71.19% in the baseline model to 92.27% with the Siamese network), demonstrating its effectiveness even with limited labeled data. Further testing, tuning, and code changes on the Unity side are required before we can implement the training system in VR and enable use of these models for developers.
Onboarding Developers to Universal Gestures
Universal Gestures was built from the ground up to be easy-to-use. Included with our package are several example models that can be used instantly (such as thumbs up and peace signs) and prefabs that can be dragged into Unity without writing any code. Additionally, we've included a training scene that developers can test in Play Mode, which allows them to train gestures without further configuration. Finally, we've created extensive documentation and resources on how developers can get set up in their project in minutes. Below is a video tutorial created by Brian that guides you through how to install and use Universal Gestures:
Future Goals
Universal Gestures is now in preview. In the near future, we will begin roll out new features, notably:
- Access to training and inference for our dynamic one-hand and two-hand models, and our specialized few shot models. These need more testing and refinement before they're ready for a general release
- A playground scene where developers can test the usability of their gestures in a minigame, developed by us
- Rolling out new UI for our training scene (Spark made beautiful designs that we are implementing on the frontend, pictured in the thumbnail)
- Taking developer feedback for wishlist features/shortcoming of our module
Links
We build something new at Reality Labs every week. For students at Waterloo who wish to join the team, our applications open again soon. For organizations who wish to support our work, contact our team.
Date Published
01/01/2025
Description
Authored by Justin Lin, Brian Zhang, Varun Parikh, Sandra Huang, Lily Ni, Brandon Ling, Nathanael Richard Ha Hanes, and Charlotte Ma of Waterloo Reality Labs